
A Gentle Dive Into NLP, Sentiment Analysis, and Chatbots
With all the hype surrounding chatbots, it’s safe to say that everybody
The following text is a transcript (with slides!) of my talk “How to Design and Build Chatbots that People will Love!” from Voxxed Days Belgrade 2017. It was written by Marijana, but the original recording is also available.
What’s a Chatbot Anyway?
With all the hype surrounding chatbots, it’s safe to say that everybody knows what they are by now. Let’s define what a chatbot is one more time and in shortest way possible.
A chatbot is a program that communicates with users via text or audio.
It basically takes user input, parses and analyzes it, and uses some sort of contextual state to produce the final output – the answer.
What is still unknown to many people though, is how this communication between a user and a chatbot happens in a technical sense. So, here’s a brief explanation:
It is usually facilitated via secure webhooks provided by the third party vendors you are working with.
For example, for our event chatbot Sava, we are using Messenger and Telegram, and they provide us with a secure webhook - basically just a regular HTTP which you should already be familiar with. And JSON is kind of a lingua franca here, it's the format used to exchange these messages.
Each platform has its own unique format and structure and you’re expected to build your own parsers that can interpret these into pure text, take your output and adjust it to what the platform is expecting.
Now let’s peer deeper into the technical crux of building chatbots that people will love.
Categorizing Chatbots
Knowing how to categorize chatbots will help set your expectations accordingly before you set out to build your own chatbot.
By Model
The first way of categorizing chatbots is by their model or how they generate responses. There are two chatbot models:
- Retrieval-based chatbots work by interpreting your messages, analyzing them, and finding a response in some sort of a database. These responses can be dynamic, they can incorporate context, but we are talking about a limited set of possible answers.
- Generative model works a little differently and these chatbots are more sophisticated. In theory, they can provide users with an unlimited amount of answers because they are generating them on the fly. The quality of these answers will obviously vary based on how well a chatbot has been trained.
Big tech giants are exploring the second model, a lot of research is being done on it, but nobody is really expert in chatbots yet and nobody has really built an amazing example.
By Domain
The second way of categorizing chatbots is by their domain e.g. the set of responsibilities they have and the domains are they operating in.
- Closed domain chatbots are working within a specific niche. For example, at SpiceFactory we developed a white label chatbot solution for financial institutions called Cognito. It’s meant to help you manage your payments, see offers from your bank, apply for loans, etc. This is a typical closed domain chatbot.
- Open domain chatbots should be able to communicate with users just about anything.
If we put this on a line graph with these two dimensions, you get something that looks like this:
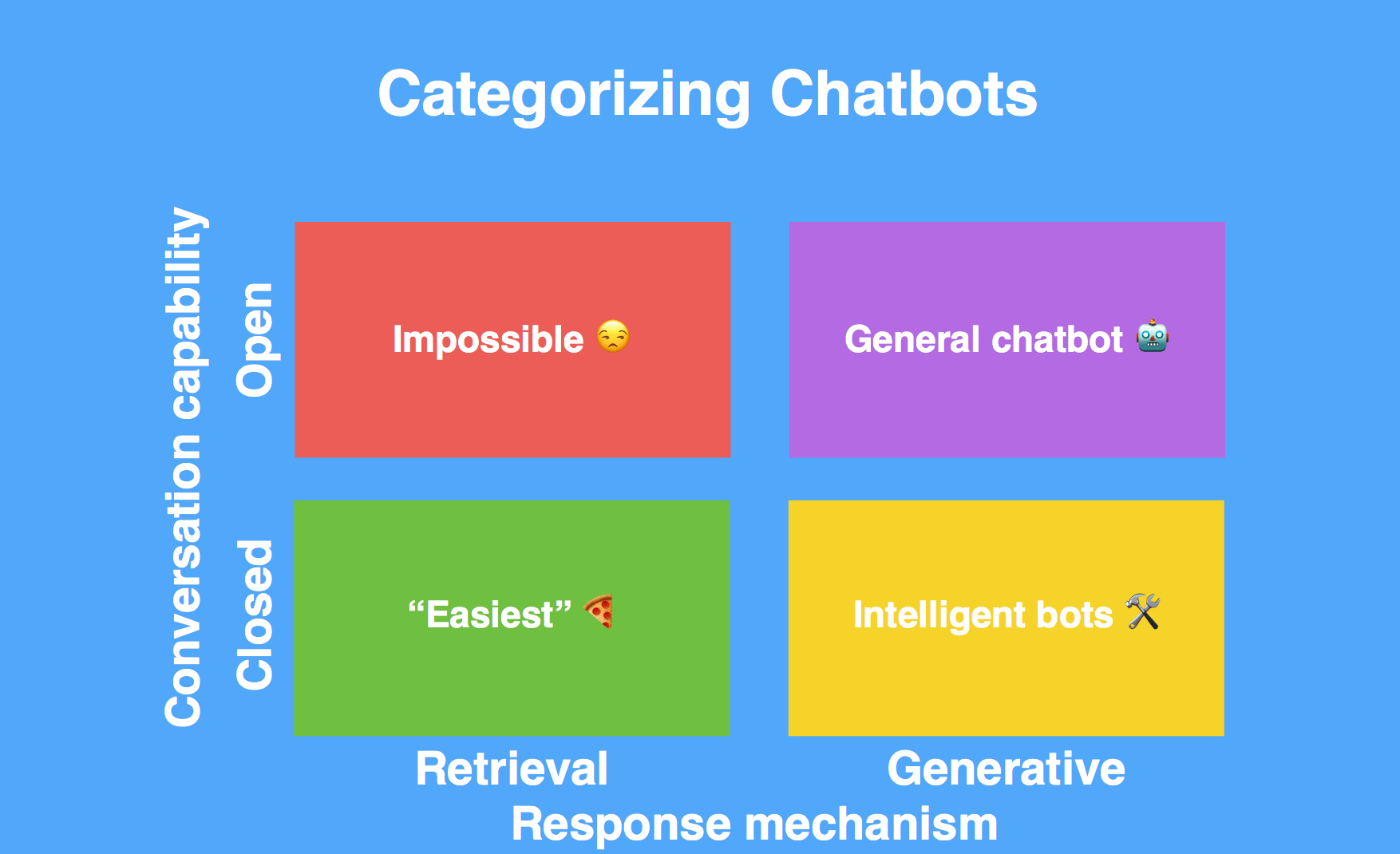
Most chatbots today fall in the green square from the image above – they are operating under a closed domain, in a specific niche, and they are using a retrieval model. So, the amount of things that they know and can do is very limited.
We are working towards the yellow box - chatbots that operate within a niche but that can generate new answers for the users. This type of chatbot could be very useful for things like technical support - solving customers’ problems on the fly and not being completely dependent on a set of previously answered questions.
The purple box is like the holy grail of chatbots - I mentioned tech giants earlier and this is where they are trying to be with products like Siri, Cortana and Alexa.
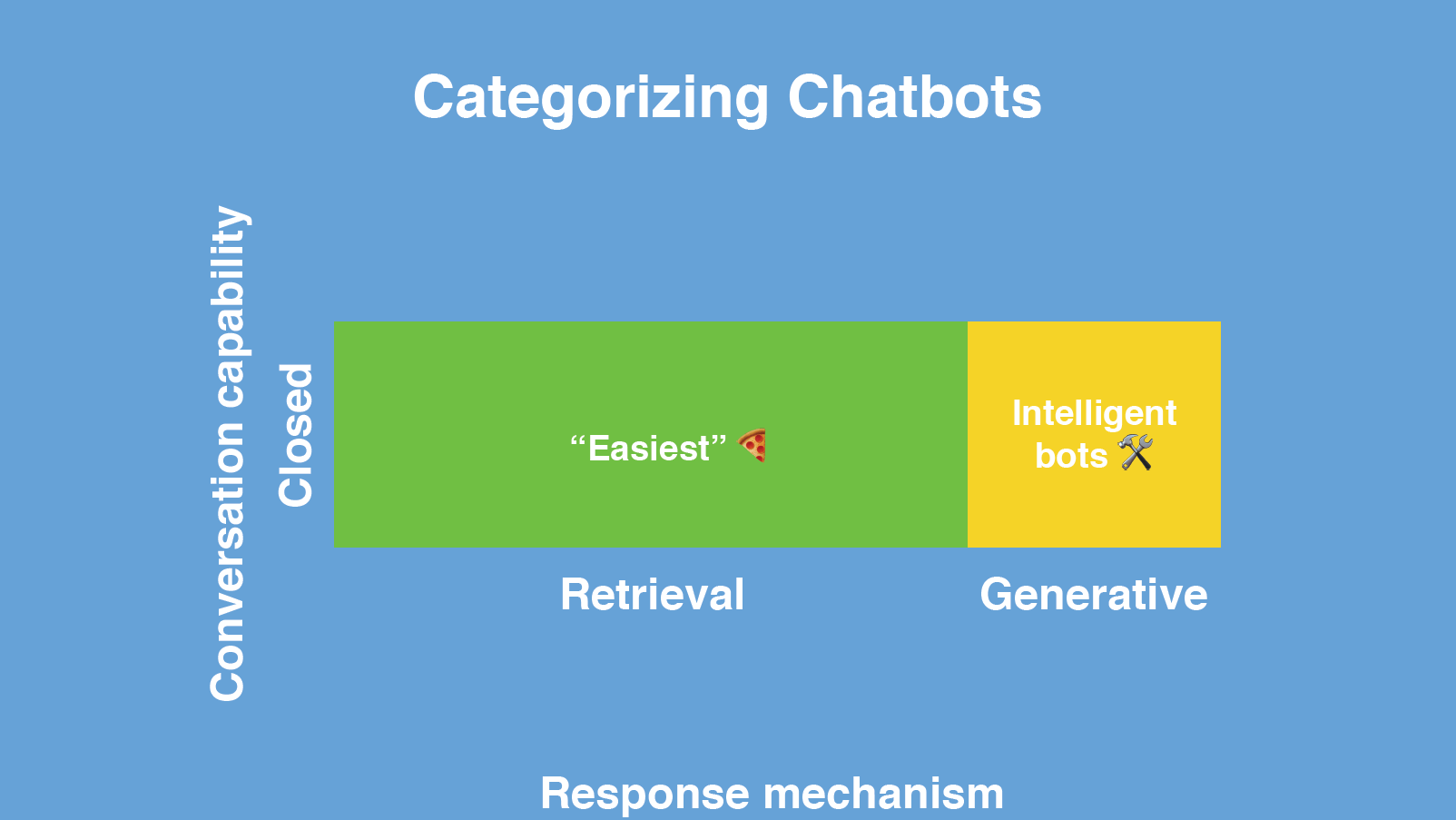
And in the coming years, this is where most of the industry will be gravitating towards - building chatbots that operate in the closed domain, mostly based on retrieval models but, where applicable, extending their functionality using generative models. When a chatbot can’t solve a problem using database answers, it will generate the answer on the fly.
So, how do we build a chatbot?
Natural Language Processing
Natural language processing (NLP) is the first major building block of creating a chatbot. NLP is a very hot field in computer science right now and it encompases a lot of different problems. Our main focus here will be on the application of NLP to understanding human language - both in terms of syntax and, perhaps more importantly, in terms of semantics.
So let's look at an example of natural language processing that you typically employ when building a chatbot.
We will start with a sentence that looks like this:
My name is Jane and I am a software engineer.
There is a conjunction there that basically splits this into two connected sentences. Maybe we could visualize it better by doing something like this:
My name is Jane and I am a software engineer.
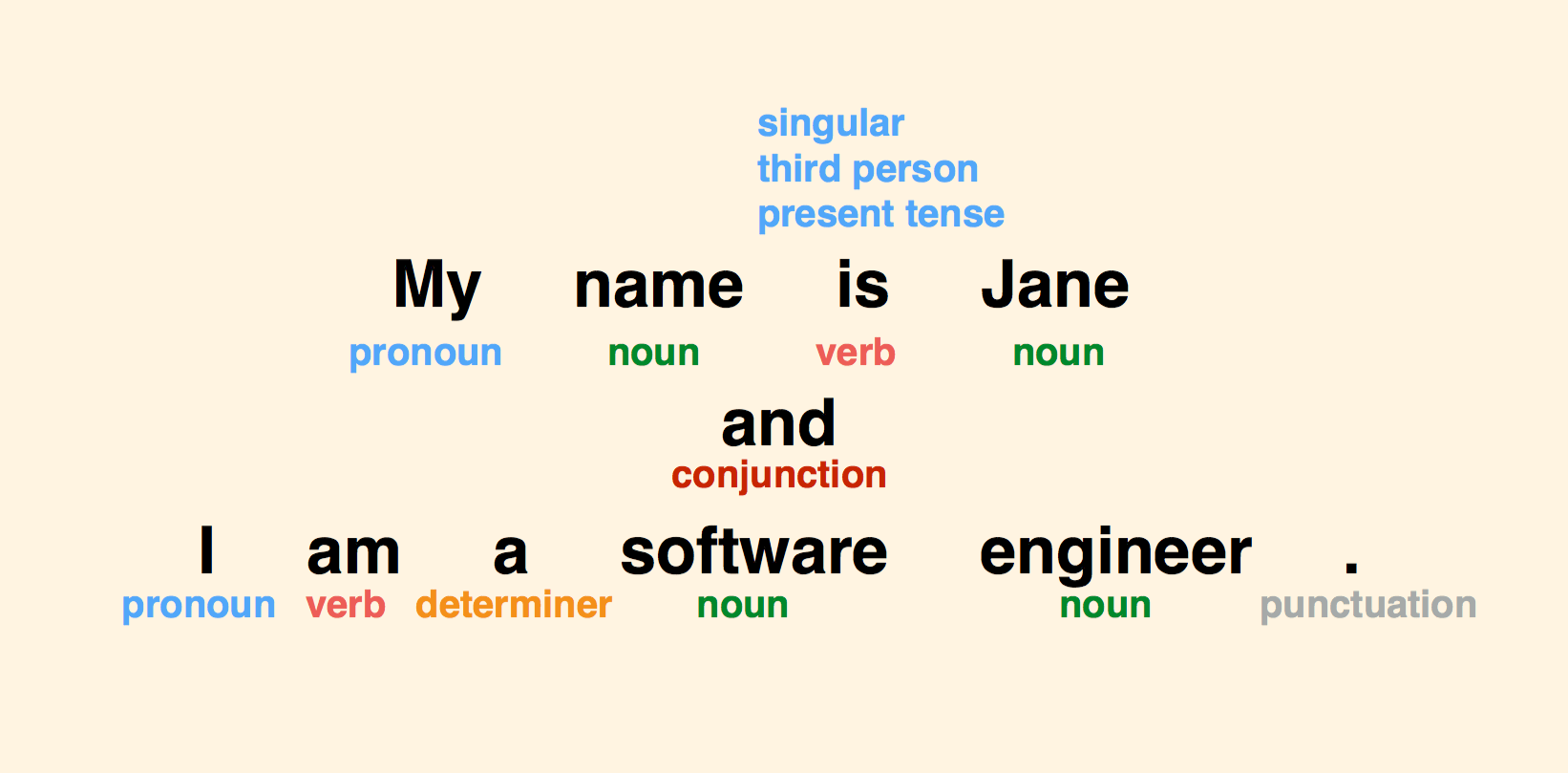
The first thing that our NLP program is going to do is tokenization - dividing this sentence into tokens. In English, this is very easy because tokens are usually separated by whitespace and punctuation marks. In Chinese, for example, it’s not that simple.
The next thing we would do once we have these tokens is analyze them in terms of syntax. The words under each tag in the following image are point of speech tags. This is something you probably learned in school.
Another thing that you should be familiar with is morphology as it can be very useful for syntax analysis.
For example, is the given token in singular or plural form? Very important when dealing with objects. Is the user buying one or multiple products? If multiple, how many products? Also in terms of verbs, is this verb in present, past or future tense? This can change the meaning and the context of a sentence completely.
When it comes to own nouns, it's important to have a good natural language processor that can help you identify first names and possibly people and organizations as soon as possible. This is very important for later when we try to extract entities within our sentences.
The next thing we want to do with this bag of words is define the relationships between these tokens.
So how do we define these relationships? We have a very cool tool for that purpose called Dependency Grammar. Once we break down a sentence it looks something like this:
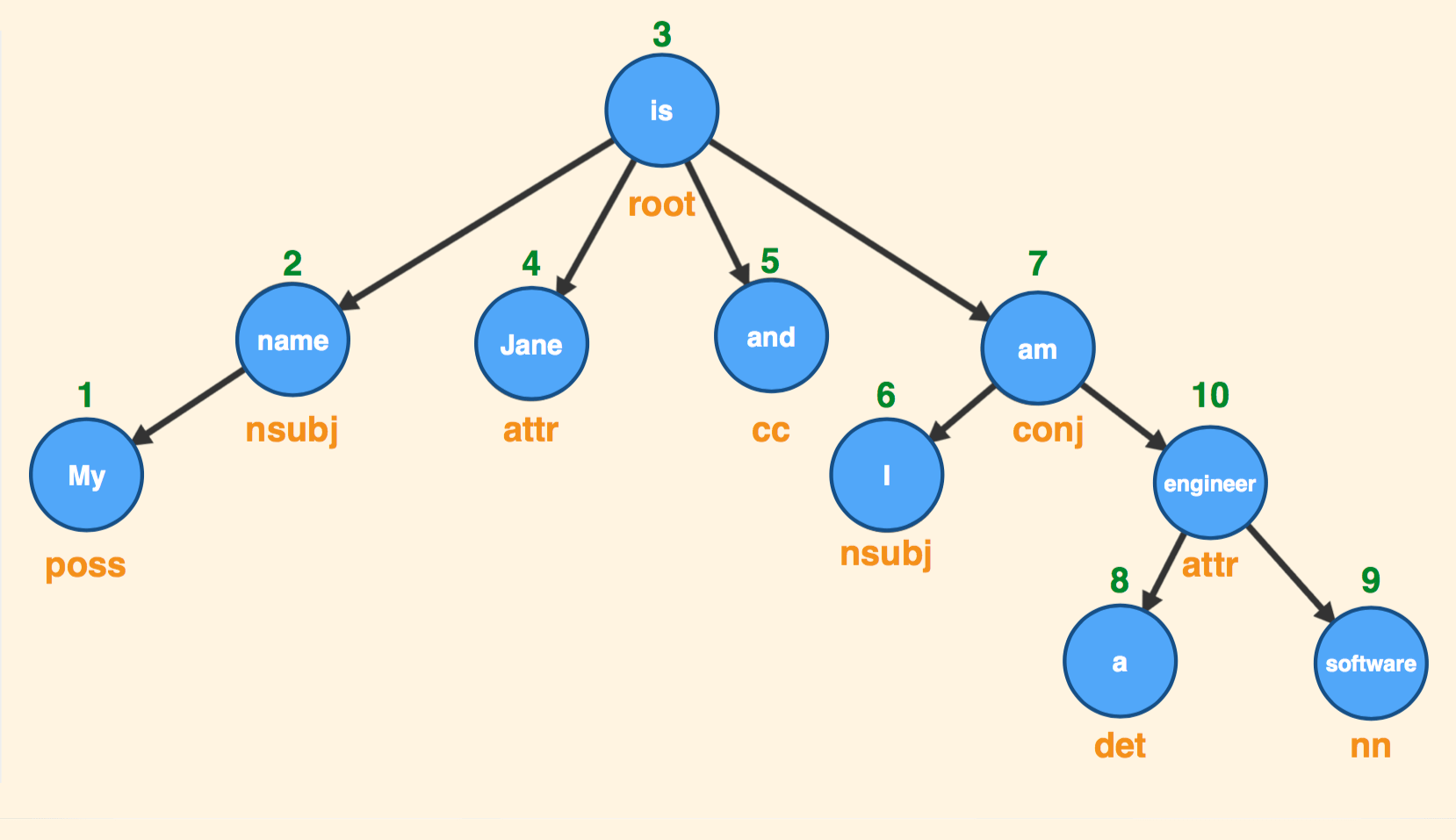
But all these dependencies are not necessarily the same as with a typical graph, each of them having a certain attribute assigned to them. The following is a more academic notation of this graph and the whole purpose of doing this is so that we can define the root of our sentence, define the subject, and analyze if the sentence is made out of multiple terms/sentences.
Syntax helps us define all these tokens, but it doesn’t help us truly understand the meaning of a sentence. We can only do that once we incorporate the idea of entities and this takes us into the field of semantics. And this is exactly what I am going to cover next.
So let’s take this sentence for example:
I want to book your conference hall for next Tuesday.
After we do the same type of analysis we did on the first sentence, we have to use a trained text classifier to extract certain entities.

This sentence has three entities that are worth looking at. The verb ‘to book’ in the context of this sentence is a domain entity - it represents a specific action. Conference hall is another domain entity in this case - what is the person booking. And finally ‘next Tuesday’ is a generic entity, a time object.
Why is it important to differentiate between the domain entity and generic entity? Because for domain entities you will have to build models and train those models to identify what you want. For generic entities, such as time and location, you can rely on pre-trained models to do this for you.
When we have the entities and our dependency grammar from earlier, we can construct a structure that basically defines this:
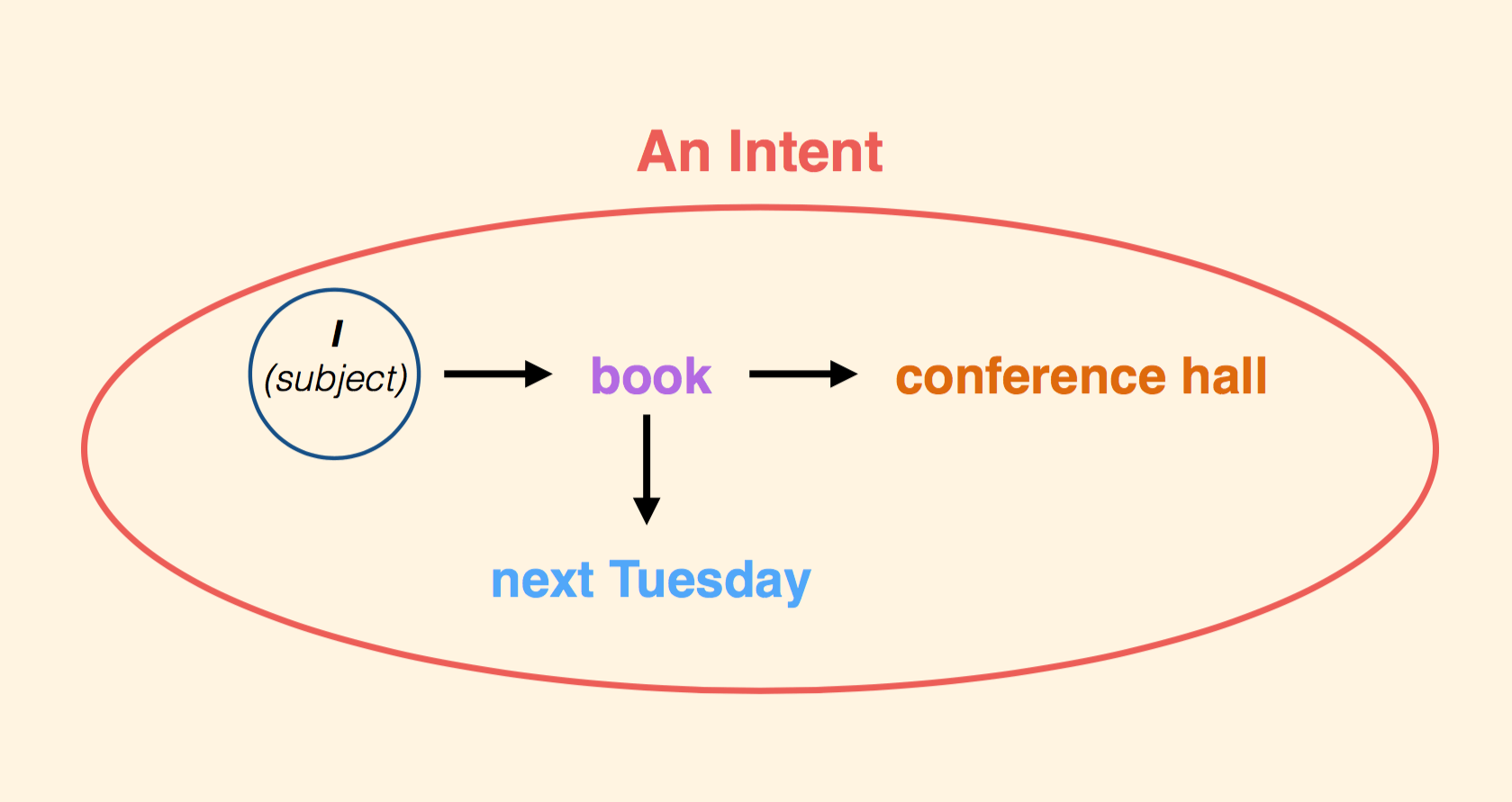
The subject wants to book something next Tuesday. This is the final output that we care about. We have our clear entities defined, we stripped down everything else, and we have clear dependencies between those entities and the subject. This is something that we might be inclined to call an Intent.
The user has issued an intent to book something. Then we could give our chatbot processor this information and it would run it by user context and some data store and say, “Oh well, this conference hall is not available next Tuesday” or “Sure, you can book it.”
All of this is a lot of work, at least I think it is. You’re probably not going to do all of it by yourself especially if you are a team of one, looking to experiment and build something really cool. There are some really good platforms you can try, including: Rasa, Wit.ai, Google Cloud Platform, IBM Watson.
Sentiment Analysis
Sentiment analysis is the second building block for creating chatbots and what makes it very interesting is that it is simply not done right yet.
We want to understand the emotion that the user is expressing and use that understanding to provide a better response or a tone of response to them. It turns out that this is really hard to do.
Let’s look at the pitfalls of sentiment analysis on a simple algorithm example.
So how would we implement sentiment analysis? Our NLP processor would tokenize words in the user’s input and then we run it through a database of words which are weighted by their sentiment. Each word having a positive or a negative score.
Then we could build something like a random forest classifier to assign probabilities to each word being used in a negative or positive context, essentially ending up with some positive or negative numerical score.
And here is what an output of such an algorithm would look like.

The algorithm is saying that this sentence has a score of positive 4. This is on a scale from -5 to 5. So far pretty good. The naive algorithm is doing a good job.
Here's another example:
“Johnny's burgers taste terrible.”
The score is -3, so the algorithm is still holding on.
Here’s a third example:
“Johnny's burgers are great, but the staff is rude.”
So is this a positive or a negative sentence? It’s really difficult to say, isn’t it? This algorithm is leaning toward ‘kinda positive’ but mostly neutral, assigning it a score of 1. This basically says that “great” in this context is more important than the word “rude.”

And here is an example of when the algorithm fails.
“This is bad.” “This is not bad.”
Both of these sentences got a score of -3. The word “not” in the second sentence is a negation. It is not saying that this should be positive, it is just neutralizing the value. So the value here should have been around zero.
You may see the solution in tweaking the algorithm so it can handle negation and you can probably do that. But language is so complex and full of nuances that it would have you tweaking the algorithm every other day. Going with simple classifiers isn't going to cut it.
So what would be less naive?
It might be easier to use a 3rd party platform like IBM’s Alchemy, part of the Watson project. Here’s how that service would interpret these two inputs.

Alchemy is understanding this correctly as a very neutral sentence. But here is something that is not very positive.
“I enjoyed the show the same way I would’ve enjoyed petting a vicious bear.”
Is today’s sentiment analysis going to predict that this is a negative sentence? Not exactly. It’s a positive with an 80 percent probability that the user is expressing joy.
There’s a very good reason why this approach to sentiment analysis is never really going to solve our problems. Because this is an objective way of defining emotions.
It doesn’t take context into account and it leaves it up to you to analyze the user’s previous behaviors. Its trying to say that every single person who said this would have meant the same thing with the same amount of emotion.
This is why so many chatbots fail. And since this is inevitably going to happen to you at some point or another, I am going to give you a word of advice…
Teach your bot to fail gracefully.
For more tips on the actual design of your chatbots and it’s personality, <a href="{{ "/blog/how-to-design-build-chat-bots-people-will-love/" | absolute_url }}" target="_blank" rel="noopener">read this article on designing bots that people will love!
Related Insights

Insight
How to Design and Build Bots that People Will Love!
Conversations are hard for bots. Master chatbot design to create amazing user experiences that drive conversions. Learn how to handle small talk and build a bot people actually love.
Read More
Insight
All You Need to Know About Designing Human-Like Chatbot Conversations
Discover how to craft chatbot interactions that feel truly human. Elevate your UX design with actionable strategies for creating natural, frictionless AI conversations.
Read More
Insight
How to Manage User Expectations in Chatbots
Users often overestimate what AI can do, leading to poor UX. Learn how to set boundaries and manage user expectations for successful chatbot interactions.
Read More
Insight
AI-Powered Chatbots Coming to an Event Near You
Struggling with event tech adoption? AI-powered chatbots are the game-changer you need. Learn how conversational AI reshapes the attendee experience and drives engagement.
Read MoreShipping production AI into a regulated industry?
Tell us the regulatory or safety constraint slowing you down. 30 minutes with a senior engineer, a deployable architecture sketch, and an honest call on whether a Bootcamp is the right next step.