
Myths and Truths About Innovating Legacy Systems
Inheriting a legacy system isn't a dead end. Uncover the strategic truths of modernizing aging software and learn how engineering leaders can turn technical debt into scalable business innovation.
When we say that we inherited a ‘legacy system’ what does that mean exactly? This usually means we’re in a situation where we need to work on a system that has been around for years and that multiple teams have worked on over time. Each of those teams had their own preferred technology stacks and very different development patterns and visions for that product.
They left behind some code, a working software that delivers certain value, as well as documentation for the entire evolution of the system that may or may not be useful to us.
When your job is to maintain this type of system, to upgrade it, and plan for some sort of improvement over the long haul, the question that arises at the project onset is what would be the right approach to take.
It also makes us think about whether the code we inherited is an asset or a liability which will then steer us in the right (or wrong) direction for tackling the project at hand.
Now, let’s start debunking some of the most common myths related to innovation of legacy systems.
Myth no. 1 Code is an asset.
Is legacy code that you inherited an asset that brings value from the start, or is it a liability?
It may seem logical that code is an asset. A software product that we build will most likely drive some revenue for the company. However, if this was true, then we’d want more code because more code would equal more profit. But we intuitively know that this is not true.
In my opinion, some code really is an asset and some doesn’t have any value for the end user. It's just piling up to make things easier for developers in the short term.
I also believe that every code is a liability in some way. If you take responsibility for legacy code and all the potential issues that come with it, writing new code will cost a lot of money.
Now, let’s visualize how one system becomes outdated in the first place.
Below is one small greenfield project. The green squares you see in the visual representation of the system are some well-written modules or features that have value for the users and they can be easily upgraded and maintained.

During the project lifecycle, sooner or later the orange squares will start to appear in the system. These orange squares represent a code that may be difficult to maintain and that makes it tricky to add new features. They could also be related to outdated documentation or some code that hasn’t been tested. In any case, these types of issues are not considered critical and things can still be improved.
But at some point ‘red blocks’ start to appear in the system because the developers made some serious mistakes and introduced poor patterns making further development of the system painful for everyone involved.
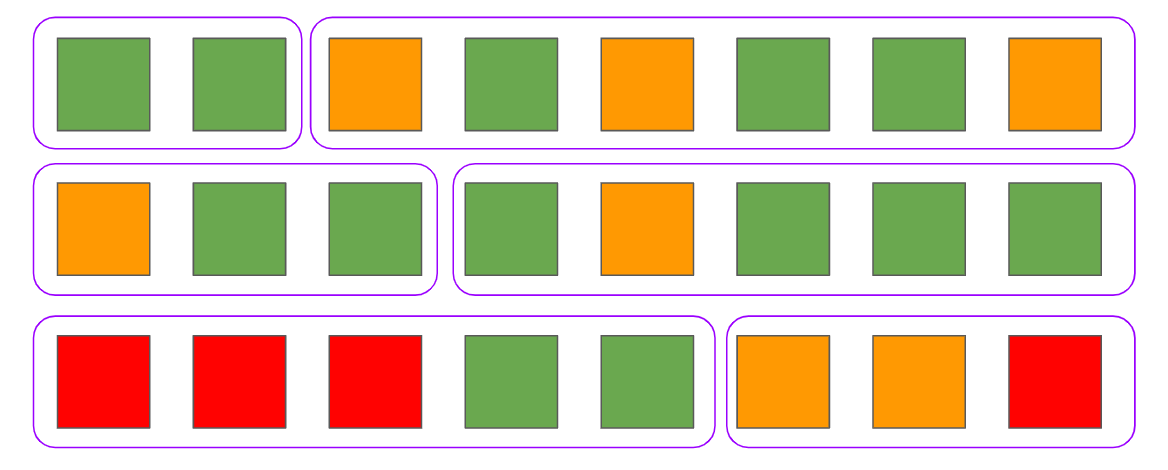
As soon as this happens, every new feature that follows becomes more difficult and more expensive. For each new ‘green square’ that we want to introduce into the system, we’re also adding more orange or red ones. This is the cost of a technical debt that we’ve created.
It’s important to remember that code doesn’t exist in isolation. One big mistake that we make has a negative impact on different parts of the system. And if we didn’t write tests properly, there’s a big chance that we won’t see this. Situations like this can slow down the project until it eventually shuts down.
So, based on the visual model we’re using, this is how a legacy system that’s been operating for years would look like:
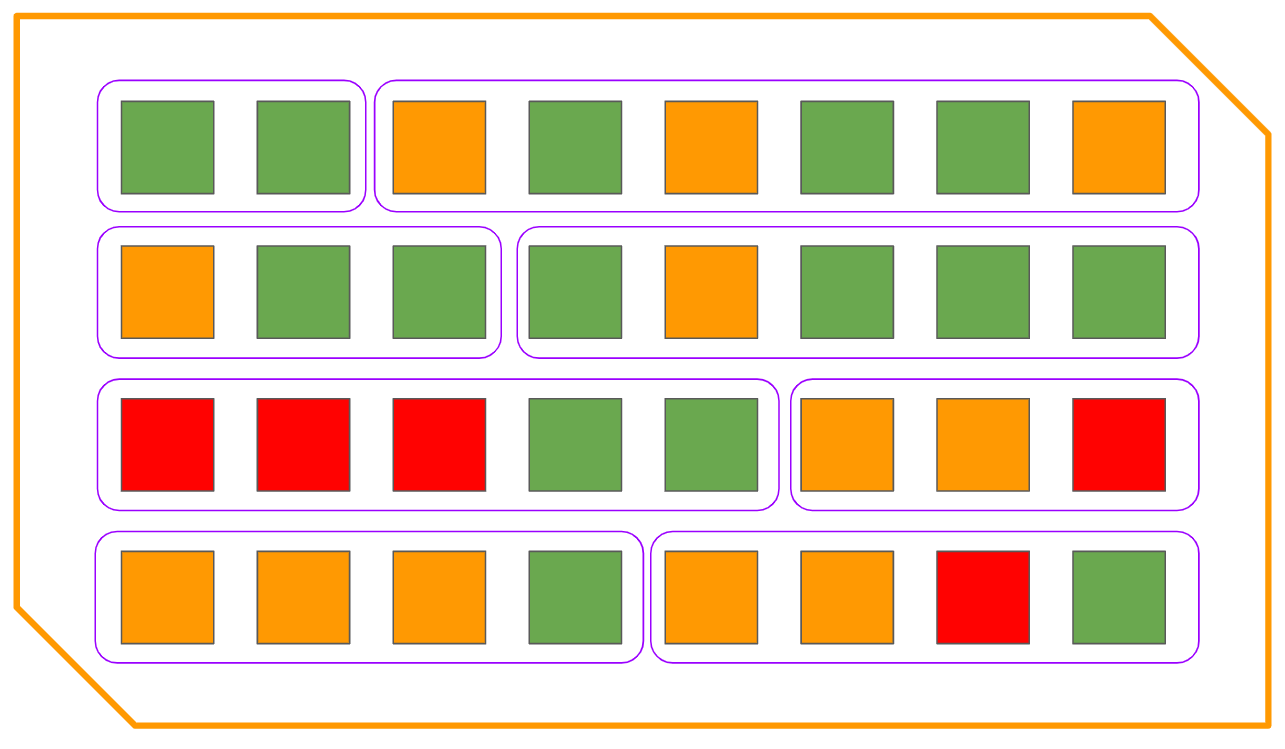
Imagine you’re tasked with modernizing it. The system has customers that are satisfied with how it works and with the value it currently delivers, but they also want to see some issues resolved and new features added.
You want to start adding new features but you know that this also introduces issues that arise from the technical debt that has been accumulated over the years.
And now we’ve come to the big question - how do you approach innovation of this legacy system? Do you start writing it from scratch or are there better ways?
Let’s take a closer look at myth no. 2 to answer this conundrum.
Myth no. 2 It’s best to start from scratch.
What would be the best way to tackle this project? Start from scratch? And how do you decide when this would be the most viable option?
If you decide to rewrite the system from scratch in a new technology, what do you do with the old system that already has paying customers while you’re working on the rewrite?
In my experience, starting from scratch is the wrong way to go. Why? Because we’re throwing away a wealth of experience and knowledge that has been accumulated in the system.
If you come in as an external team that didn’t work on the system and didn’t spend enough time going through that code base, you simply don’t have the knowledge and experience that you’d get if you just jump into the project directly.
But the biggest problem with this approach from the business perspective is that we’re not generating new value for a very long time. If you’re rewriting the system from scratch, customers will have to wait until you’re able to produce a new system with all those new features that were promised.
There are only 2 situations when it's reasonable to completely rewrite a legacy system:
- A new system isn’t a replacement for the old one. This typically happens in larger companies that are, for example, selling software to enterprise users and want to use certain components of the existing system and offer it to SMBs. In this case it might not make sense to rewrite and package it into a smaller product. The smarter approach is to develop a new system by borrowing the good stuff from the old one. You’ll make an MVP for a new product that is going to have a life of its own in parallel with the legacy system. Ideally, this new system will become better than the old one and you’ll be able to migrate customers to it over time.
- The legacy system is ‘small’ enough. You’ve done risk assessment and realized that the scope of the project is small enough that you can complete the project in time and within budget. A good exercise is to see if you’ve done projects of similar scope to this one in the past. Were you able to complete them within 3 to 6 months? Was the quality of the codebase good at the end? If the answer is yes and the current system is in bad shape, then a rewrite makes total sense.
Myth no. 3 While we’re doing the rewrite, we can maintain & improve the legacy system.
What if the existing system is large and complex and you decided to start from scratch, but you also want to maintain and improve the old system simultaneously?
In my experience, this doesn’t work.
A small company of 12 developers can’t hope to make this happen if they’re dealing with a large legacy system.
It typically goes like this. You have a complex legacy system and you start writing a new one. In the initial phase of the product engineering, things may look really good. You’re making progress, adding new features one by one, and then you discover issues in the old system that you already inherited and reproduced.
At the same time, requirements appear for adding new features in the legacy system. Now the infamous ‘scope creep’ occurs. What you’re trying to copy from the old system is constantly growing and you’re inheriting code issues because you just copied things over using new technologies.

The worst thing that can happen in this scenario is that the development team approaches this situation with the following mindset:
‘Let’s add this quickly to the legacy system, we’re retiring it soon anyway and our new system will come to replace it.”
This kind of thinking can lead to a huge failure. If it turns out that the rewrite of the new system wasn’t successful, you’ll end up with something even worse than the legacy system you started with.
Myth no. 4 Incremental modernization is the best approach.
Now we’ve come to what seems like a more diplomatic approach to modernizing our legacy system. Instead of starting from scratch, we’re going to take it one step at a time, do a refactor, eliminate any technical debt, and modernize the legacy system incrementally.
The reason why businesses/clients prefer this approach is because of the way you pitch it:
‘We’re going to tackle the issues within the system immediately and start adding new features, but the pace of development will be a tad slower because we want to do everything right.’
For clients that have smaller budgets or simply fear the risk of starting from scratch, this may seem like a great offer. They get the best of both worlds - all the new features that their customers want, fixing existing bugs, and eventually a whole new system without having to build it from scratch.
This is a really nice promise but it’s not easy to fulfil. It’s difficult to structure this process and evaluate how much we actually modernized the system and when we’re done modernizing it.
The typical approach is to identify some low hanging fruits or parts of the system that are problematic and easy to tackle, like writing some documentation, writing tests, or doing some easy refactoring. But then you’ll get to a point where you’ll have to ‘attack’ the big issues in the system - all the wrong patterns, outdated libraries, etc.
And not to forget, you promised to deliver quality new features in parallel with fixing the existing issues.
The experience has taught me that you may be able to deliver on both fronts for a while until you realize that ‘red squares’ make serious problems in certain parts of the system and make it difficult to introduce new features.
So what’s the solution for this problem?
One way is to introduce new features as microservices and decouple them completely from the existing monolith. This opens a host of new problems, but the tradeoff is often worth it. For a more proactive approach to attack the existing codebase, the Strangler pattern lends itself as a powerful methodology.
For anyone working on complex web clients (a SPA that grew out of your hands), micro frontends are a viable strategy to slowly introduce a component-based architecture. For example, we’ve had great success slowly introducing React to a product that was built entirely with jQuery and Soy templates. This made it easier to find and onboard new developers and it also made it easier for us to build highly interactive features that were simply a slog with the old stack.
There are of course entire books on this topic (see Martin Fowler’sRefactoring: Improving the Design of Existing Code), but just these methods alone will guide you in the right way as you start.
Myth no. 5 Rewrite is never a viable option so better not try it.
Finally, we come to the question of whether or not a rewrite ever pays off.
Even though I don’t think this is the best approach, some systems due to all the complexity they carry with them, have to be rewritten at some point.
This happens when you’ve exhausted all other options, you tried to tackle the legacy system from within and deal with its complexities, but you’ve learned that this isn’t really possible.
A lot of rewrites fail, sometimes due to bad management of scope and sometimes due to corporate politics. We’ve experienced both.
There are also some positive examples of rewrites: Basecamp was rewritten 2 times, both with great success.The lesson here is that the rewrite is likely to succeed if the team understands the domain and has proper support from the company.
Since the product was rewritten by some of the same people who made the first one and the whole company was behind it, it is easy to imagine it was a great environment for them to succeed. This is a clear exception, but it shows us it is smart to plan for a rewrite as you’re just starting a new product.
As our young industry grows older, we’re bound to hear about more rewrites and I’m sure new methods will arise. A lot of the world still runs on COBOL for example and we are really eager to see how the industry will tackle this problem in the coming decades.
Related Insights

Insight
Insights for Implementing Product-Led Innovation in Enterprises
Is your enterprise ready for product-led innovation? Overcome legacy roadblocks and complex structures to embed continuous innovation directly into your product strategy.
Read More
Insight
Adopting the Product Mindset in a Project-driven World
Why does software success depend on team mentality? Discover how shifting from a project mindset to a product mindset helps teams focus on solutions, not just technology.
Read More
Insight
How to Engineer for Change: Building Software That Adapts
Software change is the only constant. Learn to build resilient, adaptable systems that scale with your business. Discover our approach to future-proof engineering.
Read More
Insight
Innovating Enterprise through Vertical Software Development
Stop settling for generic solutions. Discover how vertical software development empowers enterprises to drive innovation, boost agility, and lead with industry-specific tech.
Read MoreShipping production AI into a regulated industry?
Tell us the regulatory or safety constraint slowing you down. 30 minutes with a senior engineer, a deployable architecture sketch, and an honest call on whether a Bootcamp is the right next step.